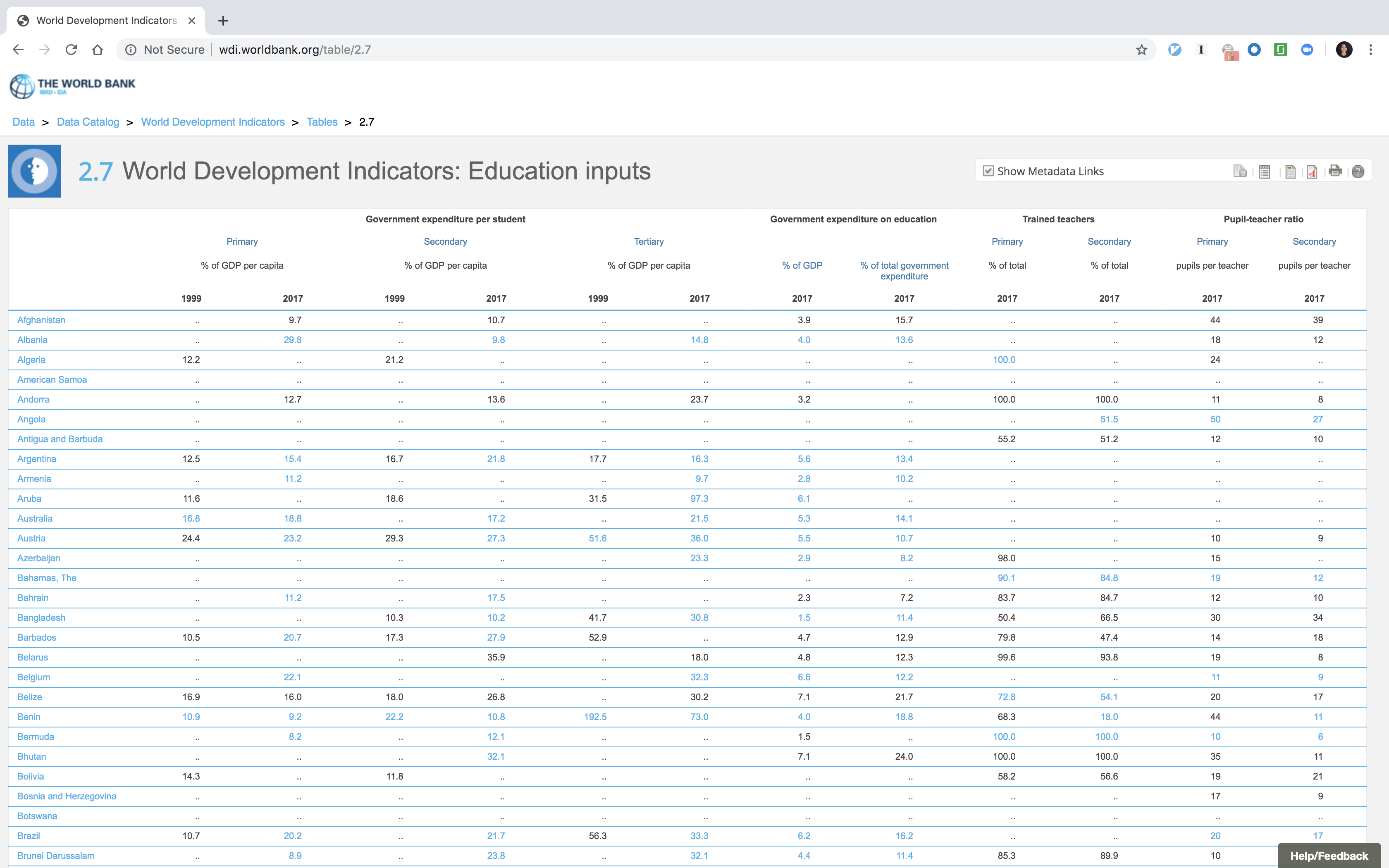
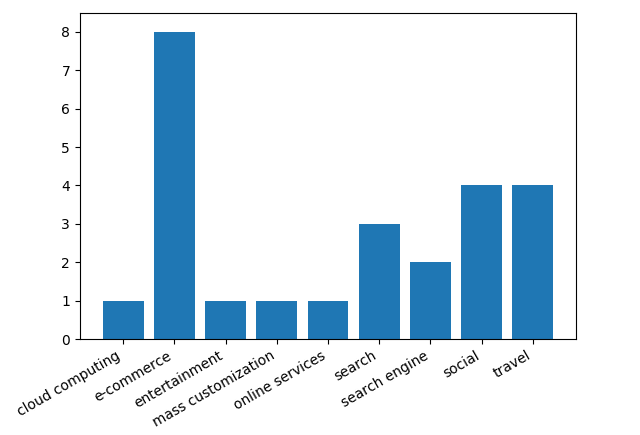
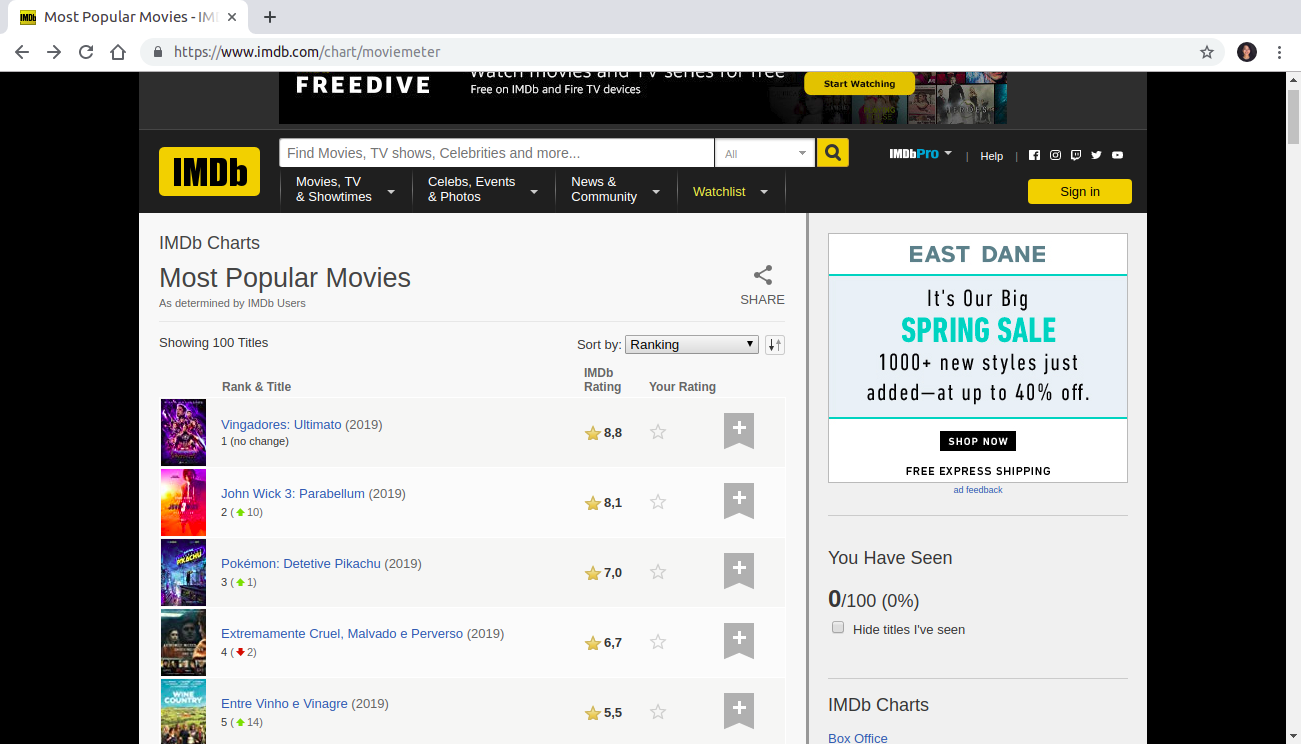
Lidiane Taquehara

- Tecnóloga em Análise e Desenvolvimento de Sistemas pela FATEC Jundiaí
- Desenvolvedora de Software na Love Mondays <> Glassdoor